Project Overview
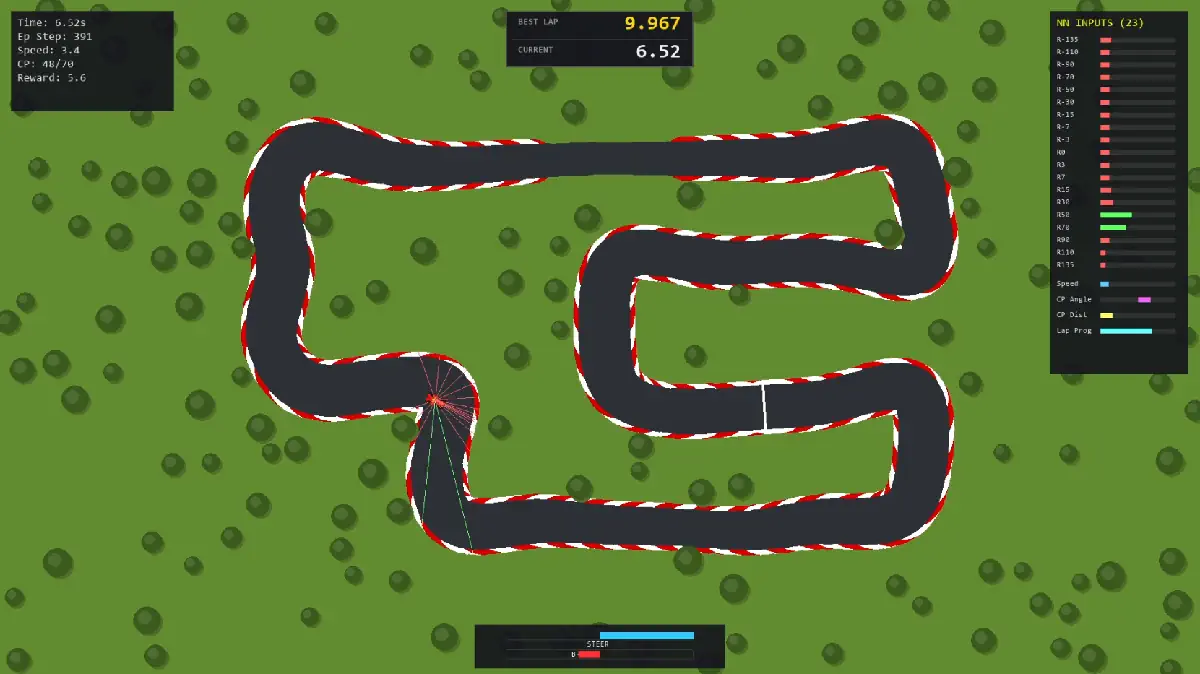
This project demonstrates the development of a Reinforcement Learning agent trained to master 2D racing lines. Built using Python and Stable Baselines 3 (PPO), it documents the AI's evolution from basic obstacle avoidance on procedurally generated tracks to precision time-attack racing.
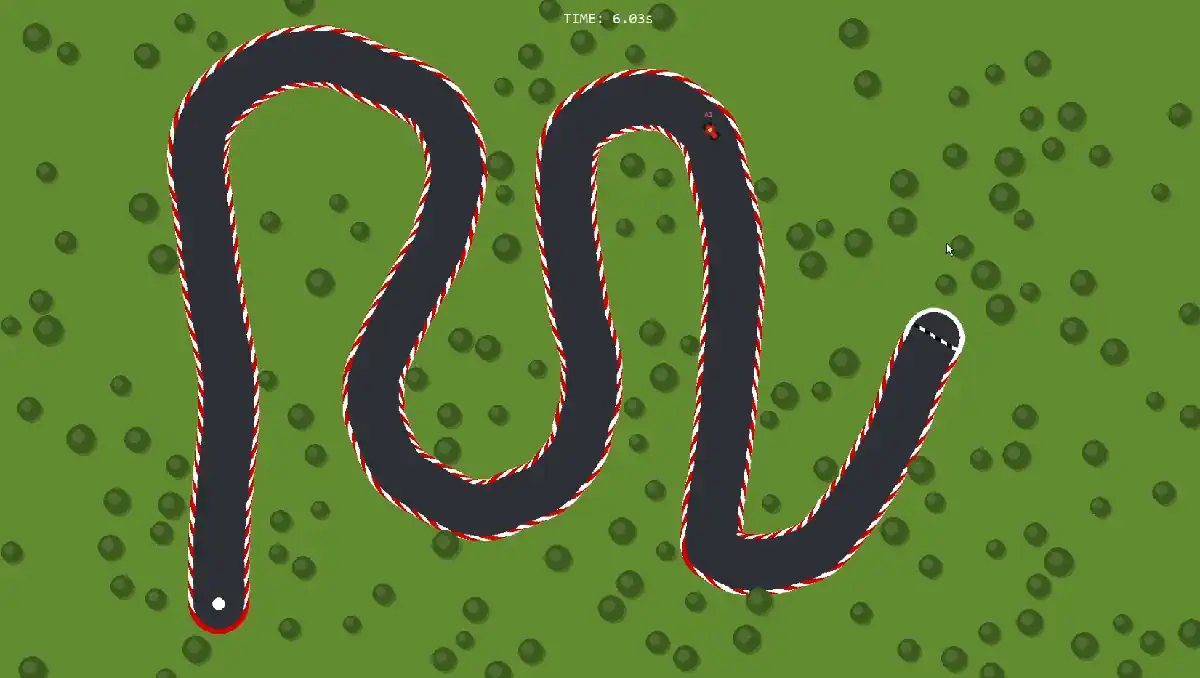
By upgrading the neural network inputs from simple Raycasts to include relative localization data (Checkpoint Angle/Distance), the agent optimized its lap times by over 9%, breaking the 10-second barrier. The project culminates in a custom "Draw & Drive" interface, allowing real-time testing on user-generated splines.
Project Showcase
Gallery
Tech Stack
- Python
- Stable Baselines 3 (PPO)
- Gymnasium
- Pygame
- NumPy
Key Features
- Reinforcement Learning (PPO): Utilized Proximal Policy Optimization to train a continuous control agent for steering and throttle.
- Procedural Generation: Developed a robust map generator creating infinite unique track layouts to prevent the AI from overfitting/memorizing maps.
- Input Optimization: Improved lap times by ~10% by augmenting LIDAR-style raycasts with "GPS" features (Next Checkpoint Angle, Distance, and Lap Progress).
- Interactive "Draw & Drive": A custom Pygame interface that processes user-drawn lines into driveable physics meshes, allowing instant simulation of the pre-trained agent on novel geometry.